杉巖智能數據處理引擎 構筑新一代智能存儲底座
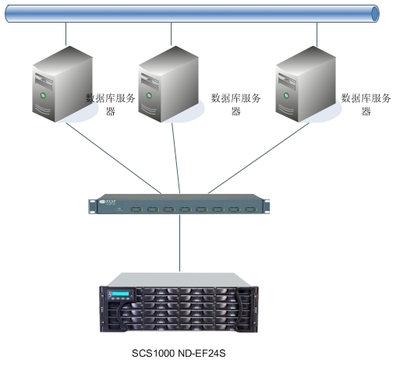
在數據驅動決策的時代,海量、多源、異構數據的實時處理與高效存儲已成為企業數字化轉型的核心挑戰。傳統存儲架構往往將“存”與“算”分離,導致數據搬運延遲、處理效率瓶頸以及整體TCO(總擁有成本)居高不下。杉巖數據憑借其創新的智能數據處理引擎,正致力于打破這一桎梏,打造面向未來的新一代智能存儲底座,為企業的數據價值挖掘提供強大、敏捷、經濟的一體化支撐。
一、 從“被動存儲”到“主動處理”:智能底座的范式變革
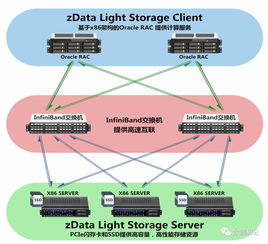
杉巖智能數據處理引擎的核心思想,是將先進的數據處理能力深度融入存儲系統之中,實現“存算一體”。它不再將存儲系統視為簡單的數據“倉庫”,而是升級為一個具備感知、分析和執行能力的“智能數據樞紐”。
- 在邊緣: 在數據產生源頭(如物聯網設備、生產線),引擎可實時進行數據過濾、格式標準化、特征提取等預處理,僅將高價值、潔凈的數據上傳至中心,極大減輕網絡與中心存儲負載。
- 在核心: 在數據中心,引擎可無縫對接AI訓練、大數據分析等應用,提供數據就地查詢、實時分析、智能標簽生成等服務,避免數據在存儲與計算集群間反復遷移,顯著加速業務洞察。
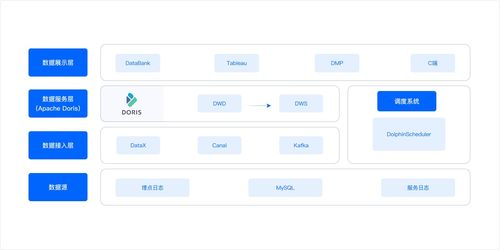
二、 引擎核心能力:賦能全場景數據服務
該智能數據處理引擎集成了多項關鍵技術,構建了堅實的能力基石:
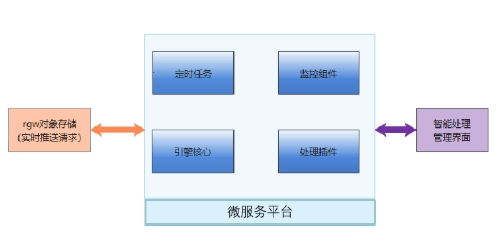
- 智能數據感知與組織: 通過內置的元數據管理、內容識別和AI模型,自動為海量非結構化數據(如圖片、視頻、文檔)打上內容標簽,實現基于語義的智能分類與檢索,讓數據“會說話”。
- 高性能統一數據訪問: 支持文件、對象、大數據(如HDFS)等多種協議,一套存儲即可滿足多樣化應用需求,消除數據孤島,簡化管理復雜度。
- 近數據處理(Near-Data Processing): 支持在存儲節點內部署輕量級計算框架或容器,使計算任務就近訪問數據,極大降低I/O延遲,特別適合AI推理、視頻轉碼、基因序列比對等計算密集型場景。
- 全生命周期智能管理: 基于數據熱度、價值策略,自動執行數據分層(從高性能NVMe到低成本歸檔存儲)、遷移、壓縮、加密和合規性保留,在確保性能的同時優化存儲成本。
- 云原生融合與彈性擴展: 全面兼容Kubernetes等云原生生態,實現存儲資源的敏捷供給與彈性伸縮,為微服務、CI/CD等現代應用架構提供持久化、高可用的數據服務。
三、 構筑新一代智能存儲底座的價值呈現
由杉巖智能數據處理引擎驅動的智能存儲底座,為企業帶來多維度的價值提升:
- 極致效率: “存算一體”架構削減數據移動開銷,將數據處理效率提升數倍至數十倍,加速業務迭代與創新。
- 顯著降本: 通過數據自動分層、壓縮和精準生命周期管理,有效降低總體存儲成本;一體化方案也減少了硬件堆疊和運維復雜性。
- 敏捷賦能: 開箱即用的數據處理能力和多協議支持,使開發與數據團隊能快速獲取所需數據服務,聚焦業務邏輯而非基礎設施調試。
- 深度智能: 將AI能力注入數據存儲的各個環節,從管理到應用,釋放非結構化數據的深層價值,驅動智能化業務場景落地。
- 安全可靠: 內置的企業級數據保護、加密與多副本機制,確保數據資產在全生命周期內的安全、可靠與合規。
四、 展望:面向未來的數據基礎設施
隨著5G、AI、物聯網的深入發展,數據洪流將持續洶涌。杉巖智能數據處理引擎所代表的新一代智能存儲底座,正是應對這一趨勢的關鍵基礎設施。它不僅是數據的承載者,更是數據的加工者和價值提升者。隨著引擎算法的持續優化與生態的不斷豐富,智能存儲底座將更加自主、協同和無感地融入企業數據業務的方方面面,成為數字化轉型進程中不可或缺的智慧基石。杉巖數據正通過這一創新,助力千行百業構建面向未來的數據核心能力,在數據浪潮中穩健航行,智贏未來。
如若轉載,請注明出處:http://www.oemodm.net.cn/product/42.html
更新時間:2026-04-08 08:50:49